Parallelization
I recently released one of my biggest projects yet into the wild: Dynamic Water Physics, a plugin which allows you to add realistic boat physics to your Unreal Engine game. It was a much bigger success than I had anticipated, prompting me to get right to work addressing some of the feedback I was receiving from my users. My first update sought to address more practical concerns, such as being able to define custom meshes which could be used by the water physics system to determine the shape of your boat. You can find information about this system, and other updates at the Patch Notes page.
Once I had addressed the more feature-heavy requests I turned my attention towards something which none of my users had yet to comment on, but something which I cared a great deal about: Performance. The plugin at this stage did not perform poorly. In fact, a rather large scene with some rather complicated water physics setups including multiple boats, boxes, airplanes, and other simulated shapes totalling in around 30 objects were able to complete their simulation in well under 2ms.
Right around this time a user asked a question on the product page concerning performance.

What he didn’t know was on that very same evening I had more than doubled the performance of my water physics solution by implementing one simple technique: parallelization.
Almost all modern systems come with 4 or more cores. In fact, if you bought a computer during the last couple years there’s a high chance you will have significantly more cores than even that! It is therefore incredibly important that parallelization is part of our plan when we start thinking about making our code run faster.
Now there’s few ways we could go about structuring my particular water physics algorithm to utilize parallelization. This algorithm primarily works by integrating the forces across an object by creating a triangulated hull around it and then calculating the local forces for each triangle. These forces can then be added together for our final acting force which is passed onto the physics engine (in our case, PhysX or Chaos). One might reason that it would be best to try and run this step in parallel, as calculating the forces this way must be rather expensive. However, there are a few things which needs to be considered first.
CPUs loves arrays. No, really, arrays are FAST. In fact, based on some testing by Malte Skarupke, if you are using trivial keys such as an int you might be better of doing a linear search on an array than to use a hash-map with up around 150 elements. I am not going to go into too much depth as to why this is the case, however it should suffice to say that your CPU loves predicable work that allows it to take full advantage of all tricks which makes modern CPUs so damn fast. These tricks include, but are not limited to, cache locality, speculative execution, and out of order execution. Now I’m not claiming that these are all sure-fire ways of making your code run fast. All algorithms are different and you need to do some proper profiling before you can determine with any degree of confidence what is making your code run slow.
So let’s do that, let’s do some profiling! Unreal comes with a built-in graphical profiler called Unreal Insights. This profiler is great at allowing you to get a very detailed overview the execution-flow of your program. I’ve placed the relevant cycle stats in my code and started the game with the profiler attached, so let’s take a look at what it tells us.
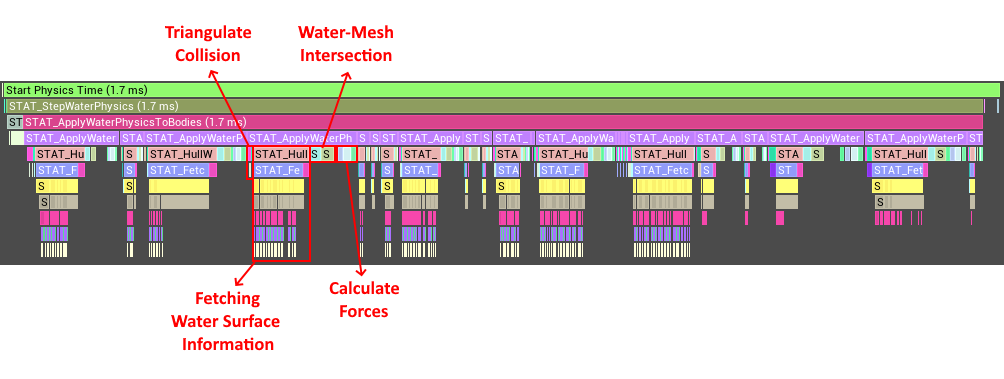
As we can se here the vast majority of time is spent fetching information regarding the water-surface. In fact, the parts related to calculating the actual forces in tiny in relation to this. This is most likely due in part to the reasons mentioned above. CPUs love to iterate predicable data-structures doing the same thing over and over. There is therefore a high risk that parallelizing this step separately from the rest of our algorithm would negatively impacted performance due to the added overhead of sharing the data between threads, and the reduced ability for the CPU to iterate a very predicable data-structure.
Ultimately I decided that instead of parallelizing any individual part of this algorithm, I would run the entire thing in parallel. The good thing with this approach is that it would be relatively simple to implement, reducing risk of creating race conditions or other nasty bugs related to threading.
Now there is a caveat, and that is that we do not have control over what happens in the function which goes off to fetch information about the water surface. Since this plugin is designed to work with any water implementation, we cannot simply assume it is safe to call this water info fetching function outside of our main thread. This led to the first attempt at parallelization, by splitting up the workload into three discrete parts:
- Setup – This step goes through all physics bodies, filters out any bodies not part of the simulation, and then builds their triangle representation which is needed for the subsequent steps. This step can be run fully in parallel as it does not depend on any external user-code.
- Water Surface Information Gathering – This step uses the triangulated meshes provided by the setup step to gather all the relevant information needed for the final step. This step can be run either in parallel or sequentially depending on the user implementing the water suface gathering.
- Number Crunching – This is where the real stuff happens. We’ve got all the information we need at this point to simple crunch all the numbers and calculate our final forces, should be a breeze!
So, now that we have a plan for how to parallelize this algorithm, let’s give it a go! Since I am writing the function for fetching the water surface data myself, and I know it is safe to call on multiple threads, I will run step 2 in parallel for hopefully even better performance.
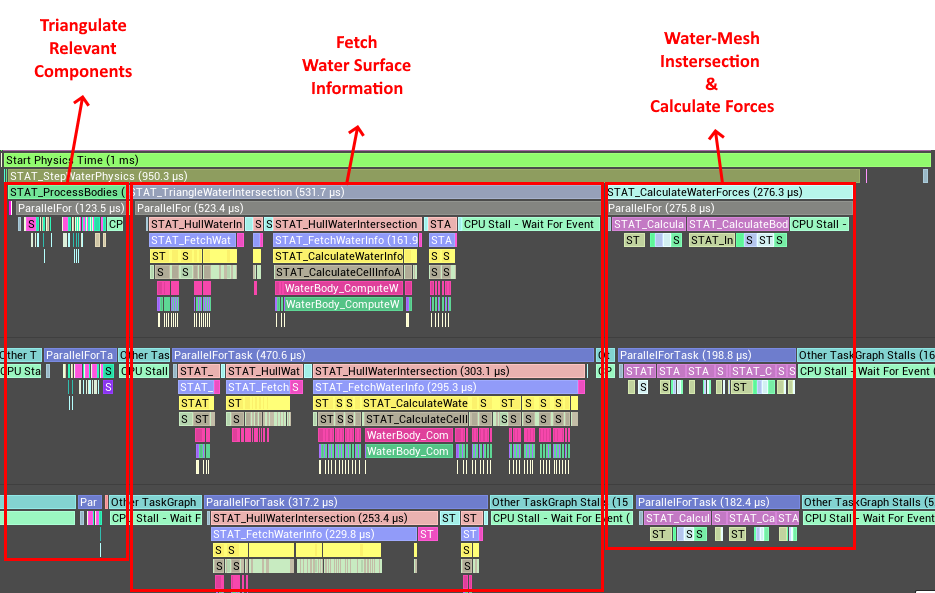
Oh wow 1ms, that’s a real improvement! However, we can se some pretty big issues straight away. The thing is, starting a parallel execution using unreal’s ParallelFor is not free. There is a certain amount of overhead involved in scheduling all the different tasks for running on the available threads. We can for example see how it takes a while for the tasks on the worker threads to get going once we call our ParallelFor. Starting and stopping this process three times introduces a fair amount of unnecessary overhead.
There is also the problem of scheduling the tasks such that we spend a minimal amount of time waiting for other threads to finish their work. Since all threads need to finish their tasks before we can move on to the next parallel step we end up with a large amount of CPU stalls. Basically a situation where one or more threads have finished their work and is now waiting for one unlucky thread who happened to get some really expensive work before they can all move on.
This is unfortunate as there is no practical reason as to why these stalling threads could not just move on to step 3 immediately. So even though this approach is great for allowing my users to run step 2 synchronously, it is pretty terrible if you wish to optimize your water information fetching algorithm for threading. I therefore decided that this solution was not enough. I reworked my scene ticking to allow for full parallelization, without having to wait for separate threads, if the scene detects that this is supported by the user.
So finally, after all of that rearranging of the scene ticking we are left with this:
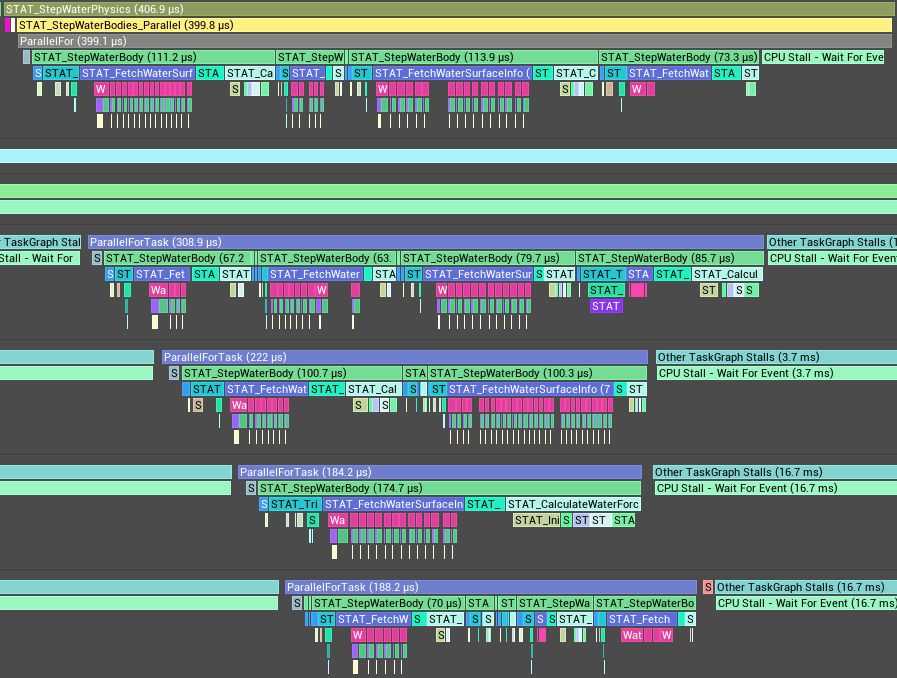
0.4ms, holy smokes! That’s a 77% reduction or about 4.3 times faster than what we started out with. That’s really good from implementing one rather simple optimization technique. It is also worth considering that these measurements were taken on a 6 year old laptop. A good laptop, but a 6 year old one non the less. With a more modern system with more and faster cores you could expect to see even better results.
So, where does this leave us? Well I think it’s pretty clear. Parallelization is awesome! In fact, I’m often surprised by the lack of parallelized systems within the core Unreal code. I guess that is just some of the code base beginning to show its age as many of the newer systems seem to utilize threading and parallelization much better.
It is worth mentioning that we can probably go ahead and make this even faster by just doing traditional optimization on each of the steps taken by the water physics scene. For example, there is no reason as to why we need to re-triangulate each of the bodies every frame, this could probably be cached. We could also improve the water surface information gathering algorithm to make it require doing less queries, filtering triangles which are fully above the water-line, or fully submerged.
Optimizing this algorithm has been a lot of fun and I hope to keep it going into the future by continuously making it faster. If you have any questions regarding optimization in unreal or have any suggestions on how to make this algorithm even faster, shoot me an email at mans.martin.isaksson@gmail.com!